摘要:随着大数据时代的来临,证券行业这种数据密集型产业对数据处理的性能有着愈发急切的需求。传统的磁盘-数据库模式的处理速度愈发不能满足需要。文中采取内存计算方式给出了该问题的一个解决方向。首先结合目前研究现状简要说明内存计算的概念,并总结出内存计算的特点。然后从单节点和多节点两个方向结合证券行业不同的业务场景给出对应的系统架构,并指出相关条件下需要关注的问题和解决方向。
关键词:内存计算;证券;单节点;多节点;架构设计
1总述
随着大数据时代的来临,证券行业的发展日新月异,交易数据量越来越大,日交易额已经步入千亿级别,2016年虽然A股市场较为低迷,以震荡为主,但是已有统计数据表明,截止2016年末,仅沪深两市场的日交易额均已达亿元级别。近几年随着交易所融资融券,股票质押,券商投行,再融资,并购重组等新业务推进步伐的加快,基金公司、券商、私募等机构投资者也对量化交易、策略交易、做市、程序化交易等有着愈发迫切的需求。沪港深市场交易种类繁多,交易数据的快速增长,大规模数据和业务场景的高时效性要求与传统的内存-磁盘访问模式产生了巨大矛盾,随着数据量的激增,在传统计算模型中的诸多问题逐渐显现出来,如内存容量的大小,原始数据缓存的寻址命中率,磁盘的I/O瓶颈(输入/输出),数据处理效率等问题,基于底层数据查询方式的局限,目前这些问题在现有的架构上都只能在软件或者硬件上初步缓解,如更新系统架构,更换更好的CPU,服务器等硬件设施,但是并不能从根本上解决这些问题。
推荐期刊:《现代审计与会计》宣传党和国家的审计(会计)方针、政策;研究和探讨前沿审计(财会)知识;交流工作经验。是热爱审计、财会事业者永远的良师益友。
内存计算的出现给这种数据密集型访问的处理方式提供了一个较好的解决方案。以内存计算为基础的内存数据库可以从很大程度上缓解目前的性能瓶颈。其支持数据直接访问的高处理效率很好的贴合了当前证券行业的业务现状。内存数据库系统带来的优越性能不仅仅在于对内存读写比对磁盘读写快上,更重要的是,从根本上抛弃了许多传统的磁盘数据管理方式,并基于全部内存数据的管理进行了新的体系结构的设计,并且在数据缓存、快速算法、并行操作等方面有相应的改进,故相比于传统数据库的数据处理速度来说有极大的提高。
本文第2节介绍内存计算的相关特点及当前的发展状况,并根据系统硬件架构的不同概述对应的设计要点。第3节针对于单节点系统框架,重点从性能,并发的角度设计系统架构;第3节针对于多节点系统框架,重点从网络,多节点间通信的角度分析系统;第5节总结内存计算架构并给出进一步研究方向。
2内存计算概述
内存计算的概念早在20世纪90年代的时候就已经有人提出并付诸实验,只是局限于当时的技术水平等条件,研究的步伐没有现在这么快。目前较权威的机构,如IBM对其说明为:针对数据访问密集型应用,为了提高数据处理效率,将数据全部或部分放置于内存,利用内存的高读取速度来提高处理速度,结合具体业务场景来看,内存计算还需要另外专门设计搭配的软
件体系架构、软件接口等[1]。据此,内存计算应包含如下几个特性:
1)大容量内存(单节点或者多节点),可将待处理的数据全部或者主要的部分存放于内存中;
2)良好的业务处理模型和接口;
3)数据规模大,较高的时效性要求;
4)支持业务的并行处理。
综上,内存计算是在大数据环境下,凭借计算机软硬件的快速发展,并通过体系架构和编程模型的重大革新,将数据的处理主要放在内存中完成,取代原来数据传统操作的新型的并发计算架构。
目前国内证券行业的蓬勃发展,大券商实力较为雄厚,经过多年的积淀,对性能,规模,灾备,监控等都有着较高的要求,分布式多节点部署可以较好的切合需要。相比较而言,小型券商也有类似的需求,只是受限于自身的发展情况,单节点已经能满足大部分需要。
1)单节点
单节点内存计算系统是指运行于单个物理节点上,拥有一个或多个处理器和共享内存(集中式共享内存,或非一致性共享内存(non-uniformmemoryaccess,NUMA))单节点上的内存计算主要是压榨CPU的性能,同时优化软件处理流程,磁盘读取方式和业务处理逻辑,同步采用新型计算架构,采用大内存和多线程并行,以达到充分发挥内存和CPU的cache的缓存处理能力,提高处理性能的目的。
2)多节点
单节点内存计算因局限于硬件资源,在处理更大规模数据的时候,由于先天架构的局限,在硬件的横向扩展方面的问题并不一定完全兼容。故分布式系统的内存计算开发和应用也逐渐丰富起来。比如以MapReduce为代表的大规模分布式内存处理技术。这种内存计算处理方式充分考虑了硬件的扩展性,天然支持多个节点(计算机/服务器)构成的集群来构建分布式内存,并通过统一的资源调度,使待处理数据有序的存储于对应分布式内存中,并根据一定的规则实现大规模数据的快速访问和并行处理。
3单节点系统设计要点
在该业务场景下,因其不涉及与外部的交互,所有的业务均是由券商自己单节点内部完成,故技术上着重考虑的是单机性能方面的问题。如系统内高并发的解决,复杂业务的接口设计,业务流程的优化等。
简要的系统框架图如下:
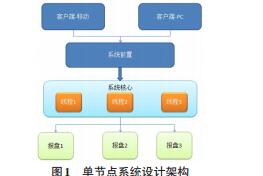
在简单的网络环境下,(暂不考虑行情等其他辅助插件),性能的提升需紧密结合业务流程,精简不需要的冗余步骤,围绕多线程并发开展业务流程设计。打好系统的底层基础架构,充分考虑后续的延展性和健壮性。
在具体的数据处理上,现也有给出较好解决方案的处理框架,如Grace[2],Ligra[3],GRACE[4]和GraphLab[5]。大体思路都是一样,都利用多核CPU和大内存,结合多线程并行技术,达到充分利用内存和CPU的目的,只是三者的处理机制和侧重点有所区别。Grace提出的是一种聚集图更新策略,针对于图划分间(线程间)进行了通信和负载均衡优化,以此提高图处理效率;Ligra的计算方式则是以图为中心,提出了一种轻量级的图处理架构,重点在于更容易实现对应的图遍历算法;GRACE重点针对的是同步/异步模式,提出了一种可以根据具体需求场景,由用户自行决定或者切换同步/异步执行的并行图处理结构。最后,GraphLab是一种基于图模型处理的机器学习算法,其并行框架是异步的。
在数据存贮上,内存数据库起步很早,如MMDB[6-7](mainmemorydatabase),在数据访问,主存和磁盘的寻址映射,内存索引结构的优化,查询的优化,日志记录和优化上都有相应的提高,现也得到了较好的效果,近几年已有商业化的解决方案出现。类似的解决方案还有,hyper和hekaton,Hyper[8]是一种混合OLTP和OLAP的高性能内存数据库;Hekaton[9]是一个基于行,针对事务处理(TP)的的内存数据管理系统,其优化过的应用可提升50倍的速度,并且完全集成了SQLServer。虽然在底层上对数据的访问有了极大的改进,但是在业务设计上也不能忽视数据的访问成本,流程的设计也需要兼顾数据的增删改查逻辑,避免无谓的资源消耗。
4多节点系统设计要点
在多节点的环境下,相对于内存读取的速度,网络间通信的读写至少要慢上两个数量级。如何解决网络内节点间通信,数据传输,节点间同步,安全问题和节点宕机的灾备恢复等则是需要考虑的重点。
简要的系统框架图如下:
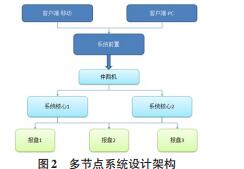
在该多节点的网络环境下,(暂不考虑行情等其他辅助插件),底层需要加入仲裁机这个角色,承担负载均衡,排队等职责,用来均衡多系统核心的负载,并对数据包进行去重,排序来保持业务处理的可靠性。网络节点的布置中还需要用相应的网络协议和对应的链路访问机制来维护节点间的路由状态和链路畅通,最常用的如OSPF(OpenShortestPathFirst开放式最短路径优先),RIP(RoutingInformationProtocol路由信息协议),BGP/BGP4(BorderGatewayProtocol,边界网关协议)等。
节点间通信除了上述开销之外,还需要加入容错,灾备,节点间同步等处理机制,用来保证业务状态的正确性和唯一性。由于内存数据的易失性的影响,相应数据的灾备,恢复等异常处理机制是至关重要的。重载是最容易想到也是实现起来最方便的,如MapReduce,其容错机制主要通过定期检查链路中的各个父子节点,对于故障的子节点,及时从其他子节点中获取对应的任务列表并重复执行,恢复到故障前的状态,而对于出现故障的父节点,则通过从集群中的其他父节点上复制数据备份并传输到本地后重新加载的方法来解决。需要在原有的业务处理逻辑上加入对应网络机结构的改造,需要整合多核心情况下的业务流程,确保多个核心可以充分发挥各自的能力,提高处理性能和CPU的利用率,解决负荷偏载,死锁等问题。
5结束语
本文首先初步分析了内存计算特点和发展情况,结合目前证券行业的现状,进一步阐述了证券行业面临的挑战和问题;并从内存计算的两种不同架构,机制以及模型等方面对内存计算技术的应用进行了简要的说明,并对现有的一些较好的科研成果进行了总结。当然,内存计算的研究问题还有很多需要进一步深入研究才能解决。比如,目前的多节点内存计算系统中的重演机制带来的存储开销问题,分布式共享内存[10]、内存数据库等,节点的容错方式均是通过接口来移动和复制其他节点的数据,或以记录日志重演的方式更新集群间各个节点。而这两种方法对于数据密集型的应用来说,开销和负荷太大,集群节点之间大量数据的复制带来的硬件存储的开销以及远小于内存带宽的网络传输带宽带来的漫长耗时,这都是后续需要分析和研究的问题。
参考文献:
[1]Inmemorydatabase:HANA,exadataX3andflashmemo⁃ry.2012[EB/OL].http://flashdba.com/2012/10/10/in-memorydatabases-part2/.
[2]ShunJ,BlellochGE.Ligra:Alightweightgraphprocessingframeworkforsharedmemory[C].In:Proc.ofthe18thACMSIGPLANSymp.onPrinciplesandPracticeofParallelPro⁃gramming.ACMPress,2013:135-146.
[3]PrabhakaranV,WuM,WengX,etal.Managinglargegraphsonmulti-coreswithgraphawareness[C].In:Proc.ofthePre⁃sentedasPartofthe2012USENIXAnnualTechnicalConf.(USENIXATC2012).2012:41-52.
[4]WangG,XieW,DemersA,GehrkeJ.Asynchronouslargescalegraphprocessingmadeeasy[C].In:Proc.ofthe6thBi⁃ennialConf.onInnovativeDataSystemsResearch(CIDR2013).Asilomar,2013.
[5]LowY,GonzalezJ,KyrolaA,etal.Graphlab:Anewparallelframeworkformachinelearning[D].arXivpreprintarXiv:1006.4990,2010.
[6]Garcia-MolinaH,SalemK.Mainmemorydatabasesystems:Anoverview[J].IEEETrans.onKnowledgeandDataEngineer⁃ing,1992,4(6):509-516.
[7]DeWittD,KatzRH,OlkenF,ShapiroLD,StonebrakerMR,WoodDA.Implementationtechniquesformainmemorydata⁃basesystems[J].In:Proc.oftheSIGMOD.1984,14(2):1-8.
[8]KemperA,NeumannT.HyPer:AhybridOLTP&OLAPmainmemorydatabasesystemBasedonvirtualmemorysnap⁃shots[J].In:Proc.ofIEEEthe27thInt’lConf.onDataEngineering.Hannover,2011:195-206.
[9]DiaconuC,FreedmanC,IsmertE,LarsonPA,MittalP,Stone⁃cipherR,VermaN,ZwillingM.Hekaton:SQLserver’smemo⁃ryoptimizedOLTPengine[J].In:Proc.ofthe2013ACMSIG⁃MODInt’lConf.onManagementofData.ACMPress,2013:1243-1254.
[10]NitzbergB,LoV.Distributedsharedmemory:Asurveyofis⁃suesandalgorithms[J].Computer,1991,24(8):52−60.